На современных высокочастотных процессорах программы могут эффективно выполнять сложные вычисления. Но потребности человечества с возрастающей скоростью требуют увеличения производительности процессоров умных машин. Один из эффективных способов повышения производительности — это объединение процессоров в группу для параллельной работы над одной задачей.
С целью совершенствования параллельного программирования был разработан специальный стандарт интерфейса для взаимодействия между процессами посредством сообщений - MPI (Message Passing Interface). Реализации MPI для различных платформ должны придерживаться стандарта интерфейса обмена данными между процессами.
Исходник на языке С++, прикрепленный к статье содержит примеры обмена сообщениями блокирующими функциями в среде высокопроизводительных вычислений. Установка, настройка и инициализация MPI среды на операционной системе Windows описано на веб-странице Настройка MPI для работы в Windows
Отправка и получение сообщений процессами является основным механизмом связи стандарта MPI. Интерфейс MPI предлагает множество функций для обмена данными между параллельными процессами. Такие функции условно поделены на группы, например группа функций точка на точку или Point-to-Point Communication.
Группа Point-to-Point Communication включает функции для организации обмена данными между двумя процессами. При помощи нескольких экземпляров таких функций можно организовать требуемый порядок передачи сообщений между параллельными процессами одной группы.
Исходник С++ содержит пример работы блокирующих функций обмена сообщениями между двумя процессами. Блокирующие функции отправки сообщения имеют одинаковую семантику (конструкцию) и отличаются только однобуквенным префиксом.
Функция стандартной отправки. Возвращается после отправки сообщения, не проверяет статус получения. Может буферизировать сообщение и возвращаться, не дожидаясь отправки и не проверяя существования соответствующей функции получения.
MPI_Ssend(…)
Функция синхронной отправки. Возвращается только после начала операции получения сообщения.
MPI_Bsend(...)
Функция отправки в буферизованном режиме. Возвращается после копирования сообщения в буфер отправки. Требует самостоятельного выделения памяти для буфера передачи.
MPI_Rsend(…)
Функция проверяет готовность получения сообщения, при отсутствии парной операции получения возвращает ошибку. Возвращается после отправки сообщения, не проверяет статус получения сообщения.
В случае успешного выполнения функции возвращают MPI_SUCCESS или код ошибки при неудачной отправке. Синтаксис блокирующих функций отправки:
// Стандартная отправка
int MPIAPI MPI_Send(
// Указатель на буфер отправки.
// Входной опциональный параметр.
_In_opt_ void *buf,
// Количество единиц MPI_Datatype в буфере.
int count,
// Тип данных в буфере.
// Указываются константами типов MPI.
MPI_Datatype datatype,
// Ранг процесса-получателя.
int dest,
// Вспомогательный тег для обозначения типа сообщения.
int tag,
// Коммуникатор - константа, объединяющая процессы
// в группу обмена сообщениями.
MPI_Comm comm
);
// Отправка синхронная с получением сообщения.
int MPIAPI MPI_Ssend(. . .);
// Функция требует создание буфера отправки
int MPIAPI MPI_Bsend(. . .);
// Отправка по готовности получения сообщения
int MPIAPI MPI_Rsend(. . .);
В исходном коде примера передачи сообщений для всех видов отправок применяется одна блокирующая функция получения данных MPI_Recv(…). Функция возвращает MPI_SUCCESS при успешном выполнении или код ошибки в противном случае. Синтаксис блокирующей функции получения сообщения:
int MPIAPI MPI_Recv(
// Указатель на буфер для приема сообщения.
// Входной опциональный параметр.
_In_opt_ void *buf,
// Количество получаемых единиц MPI_Datatype.
int count,
// Тип получаемых данных.
// Указываются константами типов MPI.
MPI_Datatype datatype,
// Ранг процесса-отправителя.
// Для получения данных от любого процесса
// используется константа MPI_ANY_SOURCE.
int source,
// Вспомогательный тег для обозначения типа сообщения.
int tag,
// Коммуникатор - константа, объединяющая процессы.
MPI_Comm comm,
// Сведения о полученном сообщении
// в виде структуры MPI_Status.
_Out_ MPI_Status *status
);
Исходник, прикрепленный к статье, содержит универсальную программу позволяющую экспериментировать с разными режимами передачи сообщений между процессами. Для запуска программы с определенной функцией отправки необходимо к команде запуска параллельных процессов добавить ключевое слово: название функции в нижнем регистре.
mpiexec -n 4 MPIMessagePassing.exe - запуск стандартного режима передачи сообщений mpiexec -n 4 MPIMessagePassing.exe ssend - запуск синхронного режима передачи сообщений mpiexec -n 4 MPIMessagePassing.exe bsend - запуск режима буферизированной передачи сообщений mpiexec -n 4 MPIMessagePassing.exe rsend - запуск режима передачи по готовности получения сообщения
Чтобы разнообразить эксперименты с блокирующими функциями в качестве содержания сообщения используются различные данные: структуры, целые числа, массивы символов, массивы типа int и float.
В сравнении с работой socket функций, функция получения MPI_Recv(…) не позволяет принимать данные в несколько этапов, а только всё сообщение за один прием. Размер приемного буфера можно указать больше, чем принимаемые данные, прием будет корректным. Но если размер буфера меньше размера извлекаемого сообщения, то параллельная программа завершится фатальной ошибкой: [0] fatal error Fatal error in MPI_Recv: Message truncated, error stack: MPI_Recv(buf=0x000000382ED9F520, count=71, MPI_BYTE, src=1, tag=MPI_ANY_TAG, MPI_COMM_WORLD, status=0x0000000000000001) failed Message from rank 1 and tag 0 truncated; 72 bytes received but buffer size is 71
Реализации стандарта MPI постоянно совершенствуются, и вполне возможно практическая работа функций может несколько отличаться от описания в документации.
Программный код селектора требуемого режима (или вида функции) отправки:
В прикрепленной программе для стандартной функции отправки MPI_Send() в качестве объекта обмена используется структура с различными типами: int, float, double, bool и строка с символами char.
Структура обмена данными
struct SDATA
{
int num1 = -1;
float num2 = -1;
double num3 = -1;
bool boolean1 = true;
char symbols[50] = "Hello from process ";
};
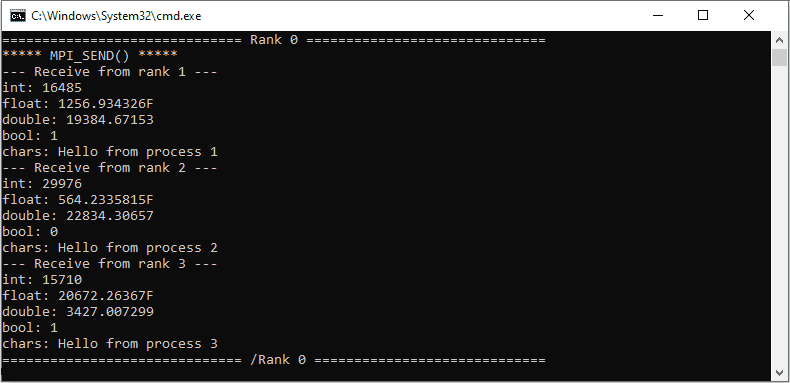
Каждый параллельный процесс присваивает случайные значения примитивным типам, а к строке приветствия добавляет свой ранг. Далее подготовленная структура при помощи стандартной MPI_Send() отправляется процессу с рангом 0, который выводит полученные структуры в окно командной строки.
Результат работы стандартной функции MPI_Send
Сообщения от процессов принимаются по порядку их рангов. Стандартная MPI_Send() допускает ожидание пока принимаются данные от других процессов и возвращает результат только после начала получения данных.
Для повышения производительности, в некоторых случаях MPI_Send() может возвратиться сразу после отправки, буферизируя сообщение и не проверяя наличие соответствующей функции получения MPI_Recv(). Такое интеллектуальное поведение обеспечивает внутренняя логика MPI реализации.
Наблюдение за поведением стандартной MPI_Send() – проверка существования парной функции получения. Если запустить несколько параллельных процессов отправки без парных MPI_Recv() работа программы завершится фатальной ошибкой: [6] fatal error Fatal error in MPI_Send: Other MPI error, error stack: MPI_Send(buf=0x0000009701CFF680, count=72, MPI_BYTE, dest=0, tag=0, MPI_COMM_WORLD) failed failed to attach to a bootstrap queue - 24552:192
Наблюдения за поведением стандартной MPI_Send() – эффект буферизации. Если раскомментировать строку: // if(i < count_processes - 1)
т.е. запретить принимать сообщение от последнего процесса и запустить одновременно несколько процессов (например 4 и более), то MPI_Send() последнего процесса может проигнорировать парную MPI_Recv() и параллельная программа завершится без ошибок.
Программный код передачи сообщений между процессами, объектом передачи является структура с переменными различных типов:
// Стандартная блокирующая функция отправки.
void BlockingSendRecv(int rank, int count_processes)
{
// Определение количества цифр в числе типа float
std::cout.precision(10);
// Получение количества байтов отправляемого и получаемого буферов.
// Для интерфейса MPI тип отправляемых данных MPI_BYTE.
int buffer_size = sizeof(SDATA);
if (rank == 0)
{
if (count_processes > 1)
{
// Получение сообщений от других процессов.
for (int i = 1; i < count_processes; i++)
{
// Структура приема данных.
SDATA recv_data;
// Наблюдение эффекта буферизации последних отправок
// при количествах процессов более 4.
// if(i < count_processes - 1)
// Процесс с рангом 0 по порядку принимает от
// других процессов структуры данных.
MPI_Recv(&recv_data, buffer_size, MPI_BYTE, i, MPI_ANY_TAG, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// Вывод данных принятого от соотетствующего процесса.
std::cout << "--- Receive from rank " << i << " ---\n";
std::cout << "int: " << recv_data.num1 << "\n";
std::cout << "float: " << recv_data.num2 << "F\n";
std::cout << "double: " << recv_data.num3 << "\n";
std::cout << "bool: " << recv_data.boolean1 << "\n";
std::cout << "chars: " << recv_data.symbols << "\n";
}
}
}
else
{
// Подготовка структуры данных для отправки.
SDATA send_data;
send_data.num1 = std::rand();
send_data.num2 = std::rand() / 1.37f;
send_data.num3 = std::rand() / 1.37;
send_data.boolean1 = std::rand() % 2 == 0;
// Номер ранга в массив символов.
char num_rank[5] = "";
_itoa_s(rank, num_rank, sizeof(num_rank), 10);
// К строке приветствия добавляем ранг отправителя.
strcat_s(send_data.symbols, 50, num_rank);
// Отправка процессу с рангом 0 подготовленную структуру данных.
MPI_Send(&send_data, buffer_size, MPI_BYTE, 0, 0, MPI_COMM_WORLD);
// Вывод отправленных данных
std::cout << "--- Sent data " << " ---\n";
std::cout << "int: " << send_data.num1 << "\n";
std::cout << "float: " << send_data.num2 << "\n";
std::cout << "double: " << send_data.num3 << "\n";
std::cout << "bool: " << send_data.boolean1 << "\n";
std::cout << "chars: " << send_data.symbols << "\n";
}
}
В примере работы синхронной функции MPI_Ssend(), каждый процесс отправляет случайное число типа int процессу с рангом 0. Процесс-отправитель выводит в окно командной строки свое отправленное число после успешной отправки. Процесс-приемник выводит числа с рангом отправителя, подсчитывает и выводит сумму полученных чисел.
Синхронная функция MPI_Send() – возвращается строго после начала извлечения сообщения процессом-приемником. При запуске параллельных процессов без функций получения MPI_Ssend ведет себя аналогично стандартной функции отправки: при отсутствии парной операции приема, процессы завершаются фатальной ошибкой.
Наблюдение за синхронным процессом отправки. Если раскомментировать строки: // if(i < count_processes - 1)
т. е. скрыть парную функцию получения для последнего ранга-отправителя и запустить несколько процессов, то одно не принятое сообщение заблокирует работу всей параллельной программы.
Программный код реализации примера синхронной отправки сообщений между параллельными процессами:
void BlockingSsendRecv(int rank, int count_processes)
{
int random_number = std::rand();
if (rank == 0)
{
if (count_processes > 1)
{
// Переменная для итоговой суммы случайных чисел всех процессов.
int total_sum = 0;
// Вывод своего числа процесса с рангом = 0.
std::cout << "\nRank 0" << " receive number: " << random_number << "\n";
// Добавление в общую сумму случайного числа процесса с рангом = 0.
total_sum += random_number;
// Получение сообщений от других процессов.
for (int i = 1; i < count_processes; i++)
{
// Получаемое число от других процессов.
int receive_number = -1;
// Наблюдение за эффектом синхронизации
// при количествах процессов более 4
// if(i < count_processes - 1)
// Процесс с рангом=0 по порядку принимает
// от других процессов целые числа.
MPI_Recv(&receive_number, 1,
MPI_INT, i, MPI_ANY_TAG, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// Вывод числа принятого от соответствующего процесса.
std::cout << "Rank " << i
<< " receive number: " << receive_number << "\n";
// Подсчет суммы принятых чисел.
total_sum += receive_number;
}
// Вывод итоговой суммы.
std::cout << "Total sum=" << total_sum << "\n";
}
}
else
{
// Отправка процессу с рангом=0 целочисленного числа.
MPI_Ssend(&random_number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD);
// Вывод отправленного числа.
std::cout << "Sent number: " << random_number << "\n";
}
}
В примере с функцией MPI_Bsend() процессу с рангом 0 отправляется несколько раз массив целых чисел. Количество повторений отправки и размер массива хранятся в отдельных переменных и в целях эксперимента им можно назначать произвольные значения.
Работа MPI_Bsend() предполагает буферизацию сообщений и требует от программиста самостоятельного резервирования памяти для буфера отправки. Объем буфера определяется в байтах и включает размер сообщения плюс размер служебных данных. Буфер подключается перед отправкой и отсоединяется после для возможности дальнейших передач сообщений.
Созданный буфер подключается к отправке вспомогательной функцией MPI_Buffer_attach(). Функция возвращает MPI_SUCCESS в случае успеха или код ошибки в противном случае.
Синтаксис функции присоединения буфера:
int MPIAPI MPI_Buffer_attach(
// Указатель на созданный буфер.
_In_ void *buffer,
// Размер подключаемого буфера.
int size
);
Функция MPI_Bsend() возвращает результат сразу после копирования сообщения в созданный буфер и дальнейшую блокировку процесса выполняет вспомогательная функция отсоединения буфера MPI_Buffer_detach().
Синтаксис функции отсоединения буфера:
int MPIAPI MPI_Buffer_detach(
// Указатель на адрес буфера
_Out_ void *buffer_addr,
// Указатель на переменную
// сохранения выходного результата.
_Out_ int *size
);
Функция отсоединения имеет два выходных параметра. Они возвращают адрес и размер отсоединенного буфера. После отправки сообщения MPI_Buffer_detach() разблокировает работу процесса и возвращает результат: MPI_SUCCESS в случае успеха и код ошибки в случае неудачи. Только после этого можно производить следующую отправку сообщения.
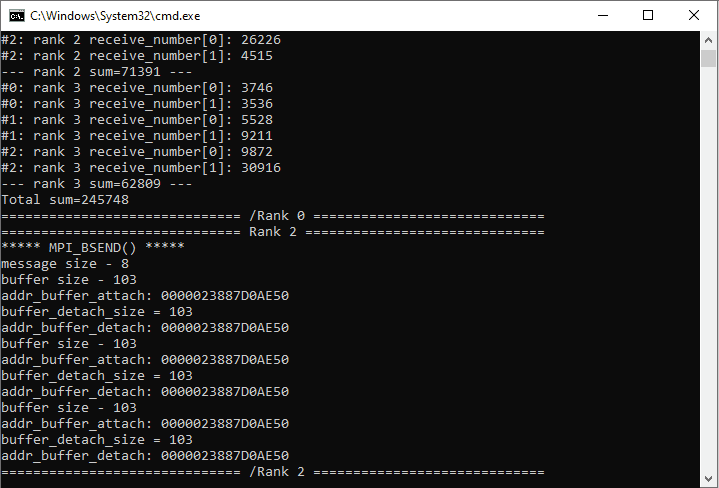
После окончания работы параллельной программы на функции MPI_Bsend() можно увидеть совпадения адресов и размеров присоединенного и затем отсоединенного буфера.
Адреса и размеры attach-detach буфера
Наблюдения за поведением MPI_Bsend() без парных функций приема. При запуске параллельных процессов отправки без соответствующих функций получения программа прерывается фатальной ошибкой:
[3] fatal error Fatal error in MPI_Bsend: Other MPI error, error stack: MPI_Bsend(buf=0x000000B7BCB5F6B8, count=2, MPI_INT, dest=0, tag=0, MPI_COMM_WORLD) failed failed to attach to a bootstrap queue - 20360:452
Наблюдения за поведением MPI_Bsend() – эффект буферизации. Если раскомментировать строку //if(i < count_processes - 1) , отключая функцию приема у процесса с последним рангом и запустить одновременно несколько процессов (например, 4 и более), то MPI_Bsend() последнего процесса может проигнорировать отсутствие парной MPI_Recv() и параллельная программа выполнится без приема данных от последнего процесса. Идентичное поведение было описано выше у функции стандартной отправки MPI_Send().
Программный код примера работы отправки в режиме буферизации:
void BlockingBsendRecv(int rank, int count_processes)
{
// Количество единиц отправляемого и получаемого MPI_Datatype.
const int count_mpi_int = 2;
// Количество повторений отправок.
int repeat = 3;
if (rank == 0)
{
if (count_processes > 1)
{
// Переменная для итоговой суммы случайных чисел всех процессов.
int total_sum = 0;
// Получение сообщений от других процессов.
for (int i = 1; i < count_processes; i++)
{
int sum = 0;
// Проверка буферизации отправки.
// Эффект проявляется при количествах процессов более 4.
//if(i < count_processes - 1)
for (int j = 0; j < repeat; j++)
{
// Инициализация массива для извлечения данных.
int receive_number[count_mpi_int] = { 0 };
// Процессор с рангом=0 поочередно принимает от
// других процессов целые числа.
MPI_Recv(&receive_number, count_mpi_int,
MPI_INT, i, MPI_ANY_TAG, MPI_COMM_WORLD, MPI_STATUS_IGNORE);
// Обработка полученных данных.
for (int m = 0; m < count_mpi_int; m++)
{
// Вывод числа принятого от соответствующего процесса.
std::cout << "#" << j << ": rank " << i
<< " receive_number[" << m << "]: "
<< receive_number[m] << "\n";
// Подсчет суммы чисел ранга-отправителя
sum += receive_number[m];
}
}
// Вывод суммы текущего ранга-отправителя.
std::cout << "--- rank " << i << " sum=" << sum << " ---\n";
// Посчет итоговой суммы принятых чисел.
total_sum += sum;
}
// Вывод итоговой суммы.
std::cout << "Total sum=" << total_sum << "\n";
}
}
else
{
// Получение размера в байтах отправляемой переменной
// для среды MPI.
int mpi_int_size = 0;
MPI_Type_size(MPI_INT, &mpi_int_size);
std::cout << "message size - " << mpi_int_size * count_mpi_int << "\n";
// Вычисление полного размера буфера отправки в байтах:
// размер отправляемых единиц плюс служебные данные.
int buffer_size = mpi_int_size * count_mpi_int + MPI_BSEND_OVERHEAD;
for (int i = 0; i < repeat; i++)
{
// Инициализация массива отправки.
int random_numbers[count_mpi_int] = { 0 };
// Получение псевдослучайных чисел для отпрвки.
for (int j = 0; j < count_mpi_int; j++)
{
random_numbers[j] = std::rand();
}
// Создание динамического массива для присоединяемого буфера
// и заполнение его нулями.
unsigned char* buffer = new unsigned char[buffer_size];
memset(buffer, 0, buffer_size);
std::cout << "buffer size - " << buffer_size << "\n";
// Прикрепление созданного буфера для отправки сообщения.
MPI_Buffer_attach(
buffer,
buffer_size
);
// Адрес присоединенного буфера.
std::cout << "addr_buffer_attach: " << (void*)buffer << "\n";
// Отправка процессу с рангом=0 целочисленного числа.
MPI_Bsend(&random_numbers, count_mpi_int, MPI_INT, 0, 0, MPI_COMM_WORLD);
// Отсоединение отправленного буфера.
// Обратите внимание первый аргумент возвращает
// адрес отсоединенного буфера.
// Второй аргумент возвращает размер отсоединенного буфера.
int buffer_detach_size = 0;
unsigned char* addr_buffer_detach = nullptr;
MPI_Buffer_detach(&addr_buffer_detach, &buffer_detach_size);
delete[] buffer;
std::cout << "buffer_detach_size = " << buffer_detach_size << "\n";
std::cout << "addr_buffer_detach: " << (void*) addr_buffer_detach << "\n";
}
}
}
Работа функции Rsend() отличается от других описанных выше функций. При построении параллельной программы обмена сообщениями посредством MPI_Rsend() приоритетное значение имеет готовность получения данных. MPI_Rsend() отправит сообщение только в случае готовности соответствующей операции получения.
Пример программного кода отправки сообщений функцией MPI_Rsend() включен в исходный код, прикрепленный к данной странице. В этом примере объектом обмена является массив чисел типа float.
Описанные выше примеры блокирующих функций используют способ получения сообщений в порядке их ранга, но не факта их отправки. MPI_Rsend() проверяет наличие соответствующей операции получения и способ упорядочивания получения сообщений по рангу в большинстве случаев вызовет фатальную ошибку. Параллельные процессы начинают и заканчивают работу в случайном порядке, и только маловероятное случайное совпадение последовательности работы процессов в порядке их ранга позволит безошибочно завершиться программе.
Например, прием сообщений по порядку работает в цикле for(int i = 1; i < num_proc; i++)
В качестве целевого ранга источника в MPI_Recv() указывается переменная i. Наглядно это выглядит так:
1. Запущены 4 параллельных процесса.
2. Ранг 3 готов отправить сообщение.
3. Ранг 0 готов принять сообщение от процесса с рангом 1.
4. Программа завершается с ошибкой: [0] fatal error Fatal error in MPI_Recv: Other MPI error, error stack: MPI_Recv(buf=0x000000A6868FFAD8, count=5, MPI_FLOAT, src=3, tag=MPI_ANY_TAG, MPI_COMM_WORLD, status=0x000000A6868FFAA8) failed Ready send from source 3 and with tag 0 had no matching receive
(Готов отправить источник 3 с тегом 0, но не имелось соответствующего получения)
Поэтому в паре с MPI_Rsend() функция получения MPI_Recv() работает с целевым источником, выраженным предопределенной константой MPI_ANY_SOURCE для готовности принять сообщение от любого процесса. Практически это выглядит так:
1. Запущены 4 параллельных процесса.
2. Ранг 3 готов отправить сообщение.
3. Ранг 0 готов принять сообщение от любого процесса (а значит и от ранга 3).
4. Ранг 3 отправляет сообщение.
5. Ранг 0 успешно принимает сообщение от ранга 3
------ следующая итерация -----
1. Ранг 2 готов отправить сообщение.
2. Ранг 0 готов принять сообщение от любого процесса.
3. Ранг 2 отправляет сообщение.
4. Ранг 0 успешно принимает сообщение
и т. д.
Программный код варианта режима отправки по готовности с функцией MPI_Rsend():
void BlockingRsendRecv(int rank, int count_processes)
{
// Количество отправляемых единиц типа float
const int count_float = 5;
// Определение количества цифр в числе типа float
std::cout.precision(10);
if (rank == 0)
{
if (count_processes > 1)
{
// Переменная для итоговой суммы слйчайных чисел всех процессов.
float total_sum = 0.0f;
// Дополнительные сведения о полученном сообщении.
MPI_Status status = {};
// Получаемые числа от других процессов.
float receive_numbers[count_float] = {0.0f};
// Получение сообщений от других процессов.
for (int i = 1; i < count_processes; i++)
{
// Процессор с рангом=0 принимает от других процессов
// по порядку их работы, но не ранга.
MPI_Recv(&receive_numbers, count_float,
MPI_FLOAT, MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &status);
for (int m = 0; m < count_float; m++)
{
// Вывод сообщения принятого от соответствующего процесса.
std::cout << "Rank " << status.MPI_SOURCE
<< " receive_numbers[" << m << "]: "
<< receive_numbers[m] << "\n";
// Посчет сумммы принятых числе.
total_sum += receive_numbers[m];
}
std::cout << "-------\n";
}
// Вывод итоговой суммы.
std::cout << "Total sum=" << total_sum << "\n";
}
}
else
{
float send_numbers[count_float] = {0.0f};
for (int i = 0; i < count_float; i++)
{
send_numbers[i] = std::rand() / 3.17f;
std::cout << "send_number[" << i << "]: " << send_numbers[i] << "\n";
}
// Отправка процессу с рангом=0 целочисленного числа.
MPI_Rsend(&send_numbers, count_float, MPI_FLOAT, 0, 0, MPI_COMM_WORLD);
}
}
Исходный код С++ программы обмена сообщениями между процессами одной группы. Исходник содержит примеры работы блокирующих функций отправки и получения: MPI_Send, MPI_Ssend, MPI_Bsend, MPI_Rsend, MPI_Recv. Среда программирования MS Visual Studio 2022. Программа тестировалась на компьютере с операционной системой Windows 10, процессор Intel Core i5 6-ти ядерный.
Архивный файл включает исходный код и скомпилированную программу. Для тестирования программы и экспериментов с исходным кодом необходимо установить среду MPI для Windows. Установка среды высокопроизводительных вычислений описана на странице Настройка MPI для работы в Windows
Скачать исходник
Тема: «Стандарт MPI. Блокирующие функции обмена сообщениями между двумя процессами»
mpimessagepassing-vs17.zip
Размер:589 КбайтЗагрузки:178